
Introduction
The surge of generative AI applications has revolutionized industries from content creation to advanced analytics. At the heart of these innovations lies large language models (LLMs), which power applications like chatbots, recommendation systems, and real-time translations. However, deploying these models for specific cases often necessitates fine-tuning to adapt the pre-trained LLMs to domain-specific requirements. Fine-tuning these vast models can be resource-intensive, leading researchers and developers to explore efficient methods like Low-Rank Adaptation (LoRA).
Understanding Fine-Tuning LLMs and LoRA
Fine-tuning is the process of adapting a pre-trained LLM to perform well on a specific task or dataset. However, this process is computationally expensive and resource intensive. LoRA addresses these challenges by freezing most of the model’s pre-trained weights and introducing low-rank decomposition matrices to specific layers. This approach drastically reduces the number of trainable parameters and computational overhead while maintaining high performance.
Hardware Requirements: Insights from AMD Experiments
Recent experiments conducted by AMD using the TorchTune library and ROCm demonstrated the fine-tuning of Llama-3.1-8B model. By integrating LoRA for efficient fine-tuning, the tests on two and more MI210 GPU showcased the ability to fine-tune mid-sized LLMs with significantly reduced memory usage and computational cost. Compared to fine-tuning with a significant number of hours or training in days, the process with LoRA took only 1.5 hours to complete on a dataset containing 2000 training instances, each with a maximum sequence length of 2048 tokens. The improved efficiency of GPU resources is shown in Figure1 for rough comparison of time-consuming ratio.
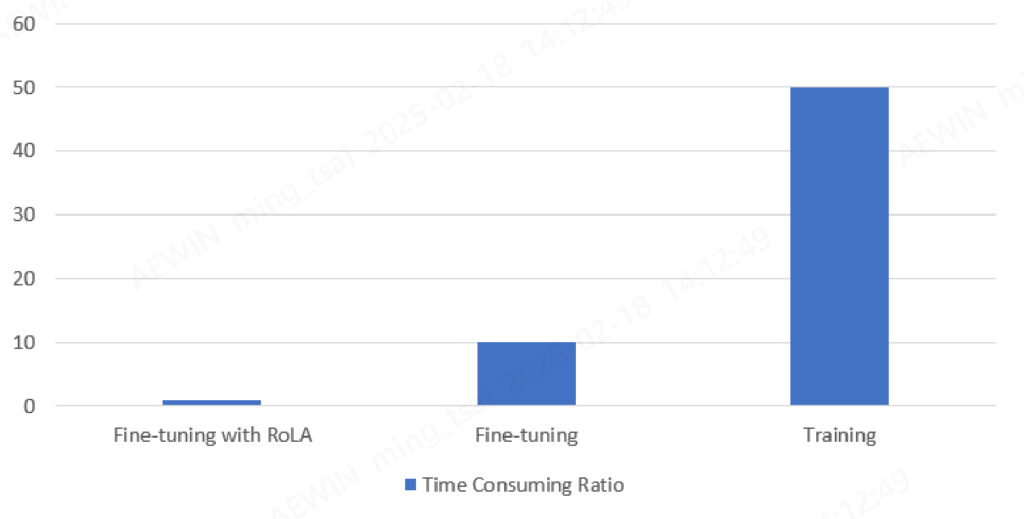
Figure.1 Ratio of time consumption for fine-tuning LLMs and training LLMs
The results also highlighted how TorchTune enables scaling from 2 to 8 GPUs with illustration of runtime improvements.
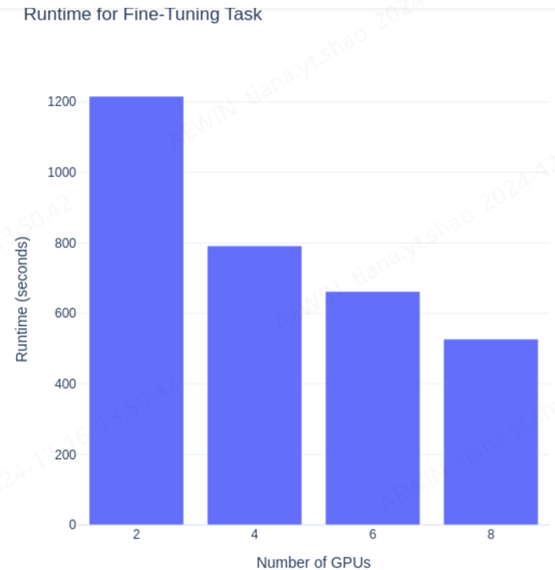
Figure.2 For experimentation purposes, AMD was fine-tuning Llama3.1-8b for just one epoch.
AEWIN has validated its edge servers with MI210 GPUs and details are included in the previous white paper published. By integrating AMD’s MI210 GPUs, AEWIN’s solutions empower organizations to harness the power of LoRA-enabled fine-tuning for domain specific Gen AI applications.
Scalable and Reliable Platforms with AEWIN Edge Servers
To meet the growing demand for fine-tuning LLMs at the edge, AEWIN’s Edge Computing Servers supporting the latest technologies with cost-effectiveness are ready to the market. Some key advantages of AEWIN’s platforms include:
- Scalability: Modular designs support flexible GPU configurations for evolving workloads. In addition to acceleration cards, multiple functional cards including NIC, QAT, E1.S storage adapter card, etc. are also available for large throughput, enhanced security, and high-speed workloads.
- Reliability: Rigorous validation helps maintain consistent performance across diverse deployment scenarios. AEWIN undergoes signal simulation, pre-simulation, post-simulation, and signal validation for PCIe Gen5 support and details are included in our previous Tech Blog/White Paper.
- Edge Optimization: Tailored for edge computing, the system features compact form factors and advanced thermal management solutions. From the design stage, AEWIN Edge Servers are engineered with short depth and front access features for easy deployment and convenient maintenance.
Summary
Fine-tuning LLMs is essential for unlocking their full potential in domain-specific applications. Techniques like LoRA optimize efficiency to make it more accessible and cost-effective. AEWIN’s scalable edge servers supporting GPUs such as MI210 provide a robust foundation for organizations aiming to deploy fine-tuned LLMs across a range of AI-driven solutions.