
Introduction
Generative AI (Gen AI) and large language models (LLMs) are revolutionizing industries with applications in language understanding and automated content creation. However, their growing complexity demands cost-efficient solutions. Retrieval-Augmented Generation (RAG) deals with the challenges by combining LLMs with external data retrieval to enhance accuracy and optimize total cost of ownership (TCO). This blog explores RAG’s features, benefits, and hardware requirements.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is a technique to address the limitations of standalone LLMs for enhanced accuracy and reliability of the AI responses. Traditional LLMs rely solely on pre-trained knowledge, which can lead to outdated or inaccurate responses, especially when dealing with dynamic queries. RAG overcomes these challenges by integrating a retrieval mechanism that retrieves relevant data from external sources before generating the answer. This approach makes generated responses align with the custom-built knowledge base.
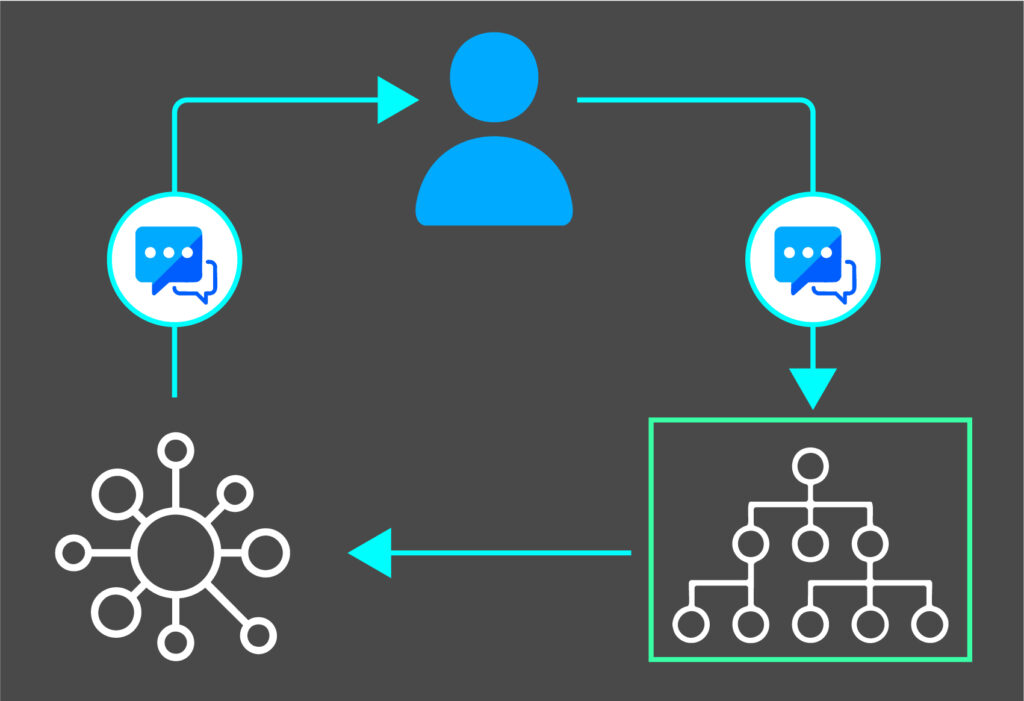
The process begins with diverse data sources including enterprise data being ingested and processed to create a structured knowledge base. When a user submits a query, the system retrieves and re-ranks relevant vectors. The most relevant context is then combined with the large language model to generate prompt response and return back to the user.
Key Features and Advantages of RAG
1. Dynamic Knowledge Integration for Improved Accuracy:
RAG enhances LLM performance by dynamically incorporating the most reliable and timely knowledge base, allowing it to provide more accurate and relevant responses.
2. Enhanced Data Privacy for Improved Security:
By querying private, secure databases during inference, sensitive information is processed locally without being shared with third party LLMs. This ensures robust privacy and minimizes exposure to external risks.
3. Cost Saving:
RAG offers a cost-effective approach to LLM customization. With retrieval mechanism, there is no need to set up extreme large-scale GPU systems for re-training LLMs which significantly reduce computational costs and time.
Hardware Requirements for RAG
To fully leverage RAG, robust hardware infrastructure is essential. Here are some key components:
1. High-Performance CPUs:
RAG requires CPUs capable of handling intensive inference tasks and high I/O throughput for data retrieval. Multi-core, high-frequency processors with the support of AVX-512 or newer instruction sets are ideal.
2. GPUs for Real-Time Inference:
While the retrieval process can be CPU-intensive, the generative tasks benefit significantly from GPU acceleration. GPUs with large memory bandwidth help meet advanced performance and low latency for LLM inference.
3. Optimized Data Access and Latency:
RAG benefits from fast storage solutions like NVMe SSDs for low-latency, high-throughput data access, coupled with high-speed networking to minimize latency during data retrieval.
AEWIN provides reliable systems powered by the latest CPU including Intel Xeon 6 and AMD Turin with the flexibility to support GPU cards, high throughput NICs, and high-speed NVMe SSDs. All solutions are optimized for power efficiency and thermal management for enabling RAG applications with the best TCO.
Summary
RAG combines dynamic data retrieval with LLMs to deliver accurate, cost-effective AI inference. By leveraging an up-to-date knowledge base, RAG is a transformative approach to achieving efficient AI deployments. As an experienced server provider, AEWIN is ready to support the new wave of innovation with our reliable and scalable Edge AI platforms.