
Introduction
Generative AI has emerged as a transformative force, unlocking new frontiers in language processing, creative content generation, and beyond. At the heart of this revolution lie large language models (LLMs), one of the core technologies behind GenAI. Large language models (LLMs) represent a breakthrough in natural language processing (NLP), exhibiting remarkable capabilities in understanding and generating human language. This technical blog will talk about what it is, highlight the prominent models in use today, and discuss the essential systems required to support them effectively.
Large Language Models
Large language models (LLMs) are advanced AI systems designed to understand and generate human language. They are trained on massive datasets and leverage billions to trillions of parameters to optimize performance.
– Segments of LLM
There are three main segments of LLM: pre-training, fine-tuning, and inference.
Pre-training
During the pre-training phase, LLMs are trained on a massive text data to learn the statistical properties and patterns of the language. The model is trained to predict the next word in a sentence, a process known as language modeling. This training phase allows the model to acquire a deep understanding of language syntax and semantics, and context.
Fine-tuning
In the fine-tuning phase, the pre-trained model is further trained on a smaller, task-specific or domain-specific dataset to adapt it to particular applications, such as text classification, text generation, or question-answering. Fine-tuning requires less data and time since the model has already learned from a vast amount of language knowledge during pre-training.
Inference
The inference phase involves using the trained model to process new input data and generate predictions or outputs which include real-time decision making, predictions generation, etc. The speed and accuracy of inference can significantly enhance operations and further enhance user experiences.
– Prominent LLMs
LLMs are characterized by their vast number of parameters, ranging from billions to trillions. These parameters are adjusted during the training process to optimize the model’s performance. Here are some of the prominent LLMs in the market:
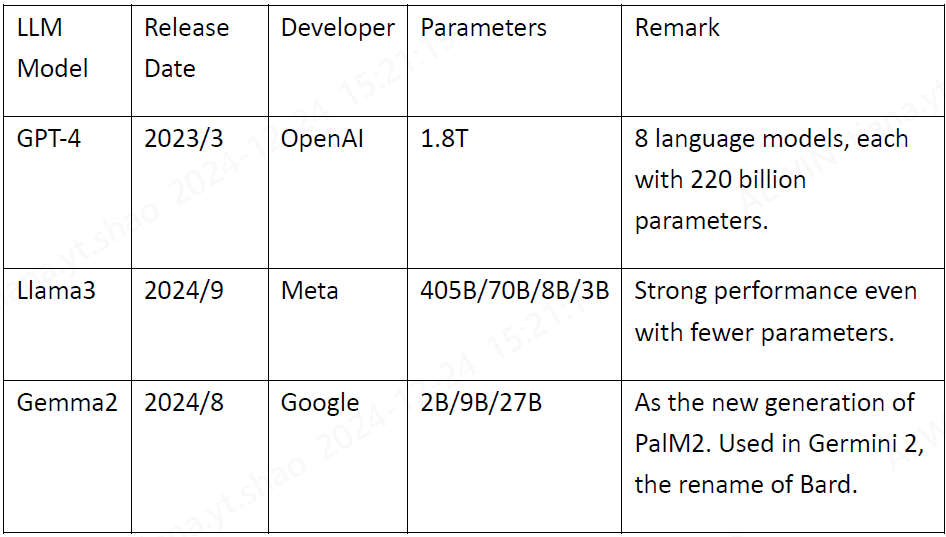
GPT Series: The Generative Pre-Trained Transformer (GPT) series, including GPT-3 and the more recent GPT-4, are among the most well-known LLMs. They are used in applications such as OpenAI’s ChatGPT, capable of generating detailed and contextually accurate text.
Llama Series: The Large Language Model Meta AI (LLaMA) series focuses on efficiency and performance, aiming to deliver high-quality language understanding and generation with fewer computational resources.
Gemma Series: The successor of Pathways Language Model 2 (PaLM 2) by Google is designed to understand and generate text across multiple languages and domains. It is the foundation of Google Germini and Germini2.
– Edge Servers and GPU Servers are Required for Running LLM
Processing Large Language Models requires performant servers while it varies in phases of pre-training, fine-tuning, and inference which make scalability of the system important to adapt to the applications.
Computing Power
High-end GPUs are beneficial to train and fine-tuning LLMs. They provide the necessary parallel processing capabilities that significantly reduce training time. As for inference, GPUs are also advantageous, though in some cases, CPUs may suffice depending on the application and model size. A powerful multi-core CPU also helps to enable efficient data preprocessing and other non-parallelizable tasks.
Scalability
As LLMs grow in complexity and size diversity, the flexibility and scalability of your infrastructure becomes critical. In addition to the scalable CPUs and GPUs, sufficient RAM and high-speed storage are required for handling large datasets efficiently. As the demand for real-time inference increases, more and more use cases applying performant edge servers to handle the workloads at where the data generated or located.
AEWIN Solutions
AEWIN offers Edge Servers and GPU Servers to respond to the market demand of various kinds of LLM applications for Enterprise AI. Reliable platforms with the ability to support performant CPU or even expanded GPUs are ready for the fast-developing on-premises AI solutions. They are perfect for dealing with real-time inference and some fine-tuning on small LLMs. Stay tunes for further insights!
Conclusion
Generative AI and large language models (LLMs) are creating new opportunities for diverse industries. The advanced models enable systems to understand and generate human-like text for a wide range of on-premises AI applications. As technologies continue to evolve, AEWIN will keep track of the trend as always to provide high-performance edge servers and GPU servers to unlock more possibilities with AI.